
BigData analytics on Kubernetes
Bigdata is a big topic since 2009, every company is seeking to process and extract information from the data that they stores. Making a complete environment from storing the data to presenting it in a simple way has been very challengin for the past years. Lot of solutions came out in the market filling just a small gap, but when you try to link everything together the BigData architecture become very complex and involves lot of different frameworks.
There is 4 different element of a bigdata environment: * Storing the data * Processing the data * Showing the analysis * Governing the data
In this short paper we will concentrate only on the second part, processing the data, more specifically processing batch data. There is lot of processing framework out there like Apache Spark, Apache Flink, Google DataFlow, Apache Pig… The solution most conventionally used, it’s Apache Spark. I stated to use Spark since the version 1.5, today the last version is the 2.4.0. Lot of things have improved since back then. Before to run a spark cluster was not an easy task, either you have an Hadoop cluster and you run spark using Yarn as a scheduler. You could also use Mesos for this purpose. But when you want to run only Spark for the time being, the deployment was complex.
Spark Architecture
Apache Spark is a distributed horizontally scalable and fault tolerant computation framework. It is composed of several workers, a driver and a cluster manager (also called Spark Master).
The Spark driver coordinates tasks that are executed by the Spark workers

The workers and the driver exchanges data between each other when needed. This exchange of data is done using random ports. This allows only spark cluster to be in the same network (probably in a unique subnet depending on your company policy)
There is two different ways to run jobs on top of Spark, first way is to run them in the client mode and the second way is to run in cluster mode.
In client mode, the driver will be run outside of the cluster, generally on the client that starts the job.
In a cluster mode, the spark Driver will run on one Spark worker. All the workers will need to have all library accessible or installed.
When you use a Data Science studio (commonly called a notebook) that uses a Spark Cluster, this notebook will hold the Spark Driver.
The new way of deploying Apache Spark
Docker Containers are more and more used in IT daylife, running Spark in containers was the obvious way to go since it helps the deployment. But it also added complexity. Spark itself it very good, but to make analytics to develop your algorithms you need a nice interface to interact with the data. Spark does not provide that, Jupyter does, but Jupyter is not natively integrated with Spark. Integrating them together using containers was though because Jupyter needed to run the Spark Driver.
A solution came out, using Apache Livy Jupyter does not need anymore to run the Spark Driver since Livy runs it and Jupyter using spark magic talks to Livy using HTTP/HTTPS. This solution is great but you can not control Spark as you would like and it adds another framework to manage.
Since the Spark release v2.2.0 the developers did a fantastic Job, they work alongside with Kubernetes APIs to be able to start Spark in Containers. The Spark driver start and stops worker pods when needed. In cluster mode, the Spark driver gets its own driver. When the Spark Tasks are completed, the driver does not consume anymore resources.
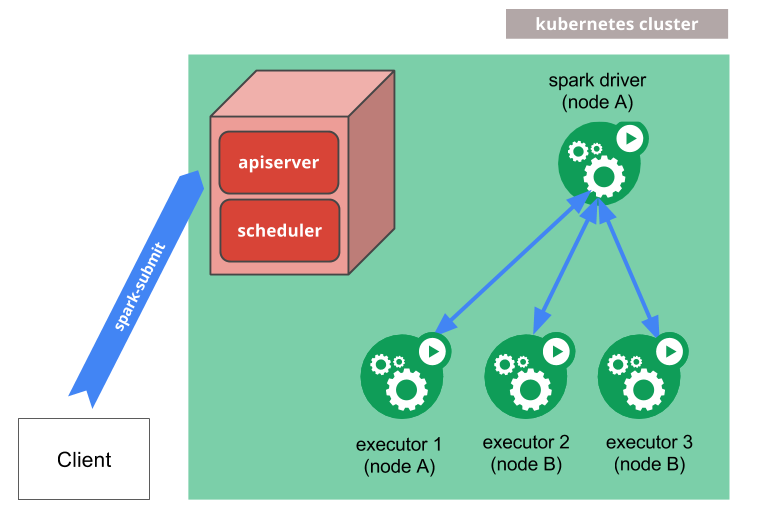
How to deploy Spark and Jupyter in kubernetes
Well, the first thing you need it’s a kubernetes cluster right? In the following examples we will be using AWS EKS (AWS Managed Kubernetes cluster). You also can run it directly on minikue but we will not be explaining this here.
Cluster creation
To create the EKS cluster, we will using Terraform to provision an AWS VPC with 3 public subnets to hold our Kubernetes Minions.
To create the VPC we will use a terraform module:
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
name = "vpc-k8s-cluster"
cidr = "10.11.0.0/16"
azs = ["eu-west-1a", "eu-west-1b", "eu-west-1c"]
private_subnets = ["10.11.1.0/24", "10.11.2.0/24", "10.11.3.0/24"]
enable_dns_hostnames = true
enable_dns_support = true
default_vpc_enable_dns_hostnames = true
tags = {
Owner = "Chuck Norris"
Environment = "test"
}
vpc_tags = {
Name = "vpc-k8s-cluster"
}
}
We create the repositories for our Jupyter and Spark worker images:
resource "aws_ecr_repository" "spark_img" {
name = "spark"
}
resource "aws_ecr_repository" "jupyter_img" {
name = "jupyter"
}
Then we create the EKS cluster:
module "my-cluster" {
source = "terraform-aws-modules/eks/aws"
cluster_name = "my-cluster"
subnets = "${module.vpc.public_subnets}"
vpc_id = "${module.vpc.vpc_id}"
worker_groups = [
{
instance_type = "m5.large"
asg_max_size = 5
worker_group_count = "2"
}
]
tags = {
environment = "test"
}
}
Deploy Jupyter in Kubernetes
Jupyter will create and delete containers inside kubernetes, if you have RBAC enabled, you need to create a Role that will be used by Jupyter to handle resources inside Kubernetes.
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: default
name: jupyter-role
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list", "edit", "create", "delete"]
Then you need to link the role to a ServiceAccount that can be used by the Jupyter pods:
apiVersion: v1
kind: ServiceAccount
metadata:
name: jupyter-sa
---
apiVersion: v1
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: jupyter-role-binding
roleRef:
kind: Role
name: jupyter-role
apiGroup: ""
subjects:
- kind: ServiceAccount
name: jupyter-sa
namespace: default
And then create a deployment for jupyter:
apiVersion: apps/v1
kind: Deployment
metadata:
name: jupyter
spec:
selector:
matchLabels:
app: jupyter
replicas: 1
template:
metadata:
labels:
app: jupyter
spec:
serviceAccountName: jupyter-sa
containers:
- name: server
image: "REPLACE_THIS_BY_YOUR_JUPYTER_IMAGE_URI"
ports:
- name: jupyter-port
containerPort: 8888
Expose the jupyter as a Kubernetes service, you could deploy this service with the type load balancer but we will use kubernetes port-forward capabilities to log to the container later on.
apiVersion: v1
kind: Service
metadata:
name: jupyter
labels:
app: jupyter
spec:
type: ClusterIP
ports:
- name: http
protocol: TCP
port: 80
targetPort: jupyter-port
selector:
app: jupyter
Log to Jupyter
Now our Jupyter notebook should be running in kubernetes, to log to the notebook, we need to access it via HTTP. To simplify this paper we will be using Kubernetes port-forward to expose the container port to our localhost.
kubectl --kubeconfig=kubeconfig_my-cluster port-forward deployment/jupyter 8888:8888
Now Jupyter is asking for a token, this token can be found in the logs of the container:
kubectl --kubeconfig=kubeconfig_my-cluster logs deployment/jupyter | grep token
Create some interesting computation other spark
For the purpose of this paper, we will calculate Pi number. Create a new notebook and insert the following code
from __future__ import print_function
import sys
from random import random
from operator import add
import os
import socket
from pyspark.sql import SparkSession
k8s_master='k8s://https://'+os.environ['KUBERNETES_SERVICE_HOST']+':'+os.environ['KUBERNETES_PORT_443_TCP_PORT']
spark_worker_image="<your docker image here>" #todo
os.environ['PYSPARK_PYTHON'] = 'python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'python3'
spark = SparkSession.builder.config("spark.app.name", "spark-pi")\
.master(k8s_master)\
.config('spark.submit.deployMode', 'client')\
.config("spark.executor.instances", "2")\
.config('spark.driver.host', socket.gethostbyname(socket.gethostname()))\
.config("spark.kubernetes.container.image", spark_worker_image)\
.getOrCreate()
In the code above, we get the kubernetes api via the environment variables that are set by kubernetes to the pod (KUBERNETES_SERVICE_HOST and KUBERNETES_PORT_443_TCP_PORT)
After that we specify the version of python we want to use, by default python2.7 is used by Spark.
the third command indicates the Spark Session by specifying the Spark Master handled by Kubernetes and some spark parameter.
One important value is the spark.driver.host this variable is set to indicate to the spark workers to communicate to the driver on the IP of the jupyter container.
The Spark Worker should have startd and be running, you can verificate using the command:
kubectl --kubeconfig=kubeconfig_my-cluster get po
Lastly just run the calculation of Pi:
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
partitions = 2 # we have 2 workers so we use 2 partitions
n = 100000 * partitions
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
And then end the spark session:
spark.stop()
Clone me
git clone https://github.com/markthebault/jupyter-and-spark-on-eks.git
TODO
- Create a terraform template that generates the jupyter.yaml with the correct ECR uri of jupyter
- Pass the container image for spark in the env environment of the jupyter container #awesome